Cell State and Clone Mapping to 10x Visium with spaceTree
This tutorial is based on public data from Janesick et al. 2023: High resolution mapping of the tumor microenvironment using integrated single-cell, spatial and in situ analysis.
In particular, we will use the following files:
- Visium files:
- Visium HDF5 file
- Visium image files
- FRP (scRNA) HDF5 file
-
Annotation files:
- Cell Type annotation file
- Clone annotation file (based on infercnvpy run on FRP data) (provided in the
datafolder). We also provide a tutorial on how to generate this file.
All data should be downloaded and placed in the data folder. You should download the data using the following commands:
cd data/
# annotation file
wget https://cdn.10xgenomics.com/raw/upload/v1695234604/Xenium%20Preview%20Data/Cell_Barcode_Type_Matrices.xlsx
# scFFPE data
wget https://cf.10xgenomics.com/samples/spatial-exp/2.0.0/CytAssist_FFPE_Human_Breast_Cancer/CytAssist_FFPE_Human_Breast_Cancer_filtered_feature_bc_matrix.h5
# Visium counts data
wget https://cf.10xgenomics.com/samples/cell-exp/7.0.1/Chromium_FFPE_Human_Breast_Cancer_Chromium_FFPE_Human_Breast_Cancer/Chromium_FFPE_Human_Breast_Cancer_Chromium_FFPE_Human_Breast_Cancer_count_sample_filtered_feature_bc_matrix.h5
# Visium spatial data
wget https://cf.10xgenomics.com/samples/spatial-exp/2.0.0/CytAssist_FFPE_Human_Breast_Cancer/CytAssist_FFPE_Human_Breast_Cancer_spatial.tar.gz
# decompressing spatial data
tar -xvzf CytAssist_FFPE_Human_Breast_Cancer_spatial.tar.gz
# renaming tissue_positions file to make it compatable with scanpy
mv spatial/tissue_positions.csv spatial/tissue_positions_list.csv
0: Imports
import scanpy as sc
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.neighbors import kneighbors_graph
from tqdm import tqdm
from scipy.spatial import distance
import scvi
from scvi.model.utils import mde
import os
import spaceTree.preprocessing as pp
import spaceTree.dataset as dataset
import warnings
import re
import pickle
import torch
from torch_geometric.loader import DataLoader,NeighborLoader
import torch.nn.functional as F
import lightning.pytorch as pl
import spaceTree.utils as utils
from spaceTree.models import *
warnings.simplefilter("ignore")
1: Prepare the data for spaceTree
1.1: Open data files
adata_ref = sc.read_10x_h5('../data/Chromium_FFPE_Human_Breast_Cancer_Chromium_FFPE_Human_Breast_Cancer_count_sample_filtered_feature_bc_matrix.h5')
adata_ref.var_names_make_unique()
cell_type = pd.read_excel("../data/Cell_Barcode_Type_Matrices.xlsx", sheet_name="scFFPE-Seq", index_col = 0)
clone_anno = pd.read_csv("../data/clone_annotation.csv", index_col = 0)
adata_ref.obs = adata_ref.obs.join(cell_type, how="left").join(clone_anno, how="left")
adata_ref.obs.columns = ['cell_type', 'clone']
adata_ref = adata_ref[~adata_ref.obs.cell_type.isna()]
visium = sc.read_visium("../data/",
count_file='CytAssist_FFPE_Human_Breast_Cancer_filtered_feature_bc_matrix.h5')
visium.var_names_make_unique()
visium = pp.convert_array_row_col_to_int(visium)
sc.pl.spatial(visium)
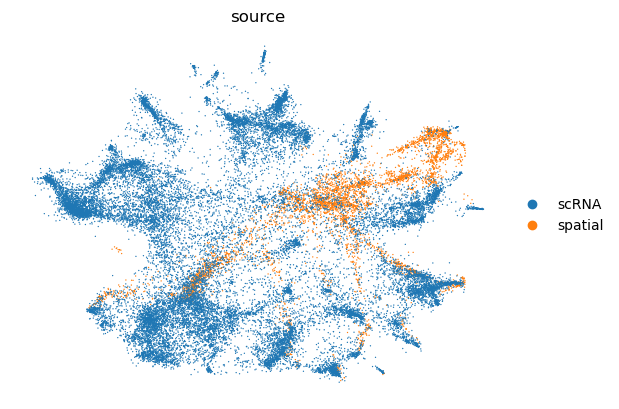
1.2: Run scvi to remove batch effects and prepare data for knn-graph construction
visium.obs["source"] = "spatial"
adata_ref.obs["source"] = "scRNA"
adata = visium.concatenate(adata_ref)
cell_source = pp.run_scvi(adata, "../data/res_scvi.csv")
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
Epoch 247/247: 100%|██████████| 247/247 [06:23<00:00, 1.46s/it, v_num=1, train_loss_step=8.42e+3, train_loss_epoch=8.08e+3]
`Trainer.fit` stopped: `max_epochs=247` reached.
Epoch 247/247: 100%|██████████| 247/247 [06:23<00:00, 1.55s/it, v_num=1, train_loss_step=8.42e+3, train_loss_epoch=8.08e+3]
cell_source.head()
| 0 | 1 | source | |
|---|---|---|---|
| AACACCTACTATCGAA-1-0 | 1.525705 | 0.691050 | spatial |
| AACACGTGCATCGCAC-1-0 | 0.806706 | 0.244148 | spatial |
| AACACTTGGCAAGGAA-1-0 | 0.953750 | -0.675919 | spatial |
| AACAGGAAGAGCATAG-1-0 | 0.539141 | 0.319413 | spatial |
| AACAGGATTCATAGTT-1-0 | 0.762749 | 0.381386 | spatial |
1.3: Construct the knn-graphs
# get rid of the number in the end of the index
cell_source.index = [re.sub(r'-(\d+).*', r'-\1', s) for s in cell_source.index]
emb_spatial =cell_source[cell_source.source == "spatial"][[0,1]]
emb_rna = cell_source[cell_source.source == "scRNA"][[0,1]]
cell_source.head()
| 0 | 1 | source | |
|---|---|---|---|
| AACACCTACTATCGAA-1 | 1.525705 | 0.691050 | spatial |
| AACACGTGCATCGCAC-1 | 0.806706 | 0.244148 | spatial |
| AACACTTGGCAAGGAA-1 | 0.953750 | -0.675919 | spatial |
| AACAGGAAGAGCATAG-1 | 0.539141 | 0.319413 | spatial |
| AACAGGATTCATAGTT-1 | 0.762749 | 0.381386 | spatial |
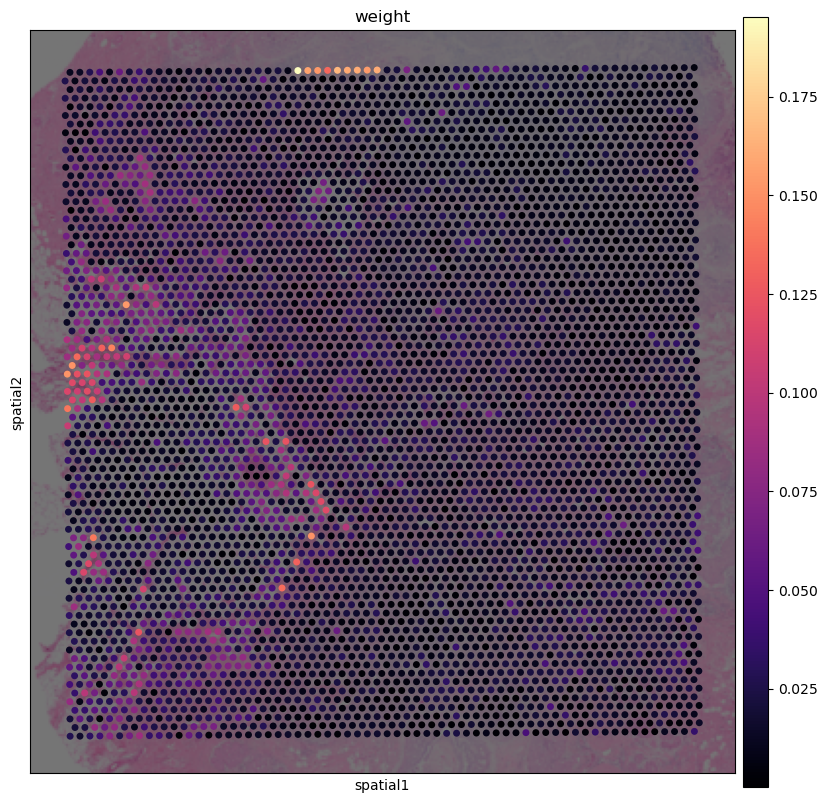
print("1. Recording edges between RNA and spatial embeddings...")
# 10 here is the number of neighbors to be considered
edges_sc2vis = pp.record_edges(emb_spatial, emb_rna,10, "sc2vis")
# checking where we have the highest distance to refrence data as those might be potentially problematic spots for mapping
pp.show_weights_distribution(edges_sc2vis,visium, 'visium')
edges_sc2vis = pp.normalize_edge_weights(edges_sc2vis)
print("2. Recording edges between RNA embeddings...")
# 10 here is the number of neighbors to be considered
edges_sc2sc = pp.record_edges(emb_rna,emb_rna, 10, "sc2sc")
edges_sc2sc = pp.normalize_edge_weights(edges_sc2sc)
Now that we are creating edge list for spatial data, please notice that we use pp.create_edges_for_visium_nodes function. This function constructs an edge list based on a 5 by 5 grid and it works well for standard Visium data and we also tested it for Visium HD. If you want to use a KNN graph instead, you can run pp.create_edges_for_xenium_nodes_global. This will create a KNN graph based on pre-defined k. If you want a more detailed tutorial tailored to Xenium data, please refer to the Xenium tutorial.
print("3. Creating edges for Visium nodes...")
edges_vis2grid = pp.create_edges_for_visium_nodes(visium)
print("4. Saving edges and embeddings...")
edges = pd.concat([edges_sc2vis, edges_sc2sc, edges_vis2grid])
edges.node1 = edges.node1.astype(str)
edges.node2 = edges.node2.astype(str)
pp.save_edges_and_embeddings(edges, emb_spatial, emb_rna, outdir ="../data/tmp/")
1. Recording edges between RNA and spatial embeddings...
2. Recording edges between RNA embeddings...
3. Creating edges for Visium nodes...
100%|██████████| 4992/4992 [00:09<00:00, 540.17it/s]
4. Saving edges and embeddings...
edges.head()
| node1 | node2 | weight | type | |
|---|---|---|---|---|
| 0 | TGAGCGATCACTAATC-1 | AACACCTACTATCGAA-1 | 0.909754 | sc2vis |
| 1 | GATCGATAGGAAGGTA-1 | AACACCTACTATCGAA-1 | 0.909715 | sc2vis |
| 2 | CAGTATTTCGGCTAGA-1 | AACACCTACTATCGAA-1 | 0.887354 | sc2vis |
| 3 | AAGGCTTAGTGCCCTG-1 | AACACCTACTATCGAA-1 | 0.860617 | sc2vis |
| 4 | CCCTTCGGTGACACAA-1 | AACACCTACTATCGAA-1 | 0.857889 | sc2vis |
Make sure that we have 3 types of edges:
- single-cell (reference) to visium
sc2vis - visium to visium
vis2grid - single-cell (reference) to single-cell (reference)
sc2sc
edges["type"].unique()
array(['sc2vis', 'sc2sc', 'vis2grid'], dtype=object)
1.4: Create the dataset object for pytorch
For the next step we need to convert node IDs and classes (cell types and clones) into numerial values that can be further used by the model
#annotation file
annotations = adata_ref.obs[["cell_type", "clone"]].copy().reset_index()
annotations.columns = ["node1", "cell_type", "clone"]
annotations.head()
| node1 | cell_type | clone | |
|---|---|---|---|
| 0 | AAACAAGCAAACGGGA-1 | Stromal | diploid |
| 1 | AAACAAGCAAATAGGA-1 | Macrophages 1 | 1 |
| 2 | AAACAAGCAACAAGTT-1 | Perivascular-Like | diploid |
| 3 | AAACAAGCAACCATTC-1 | Myoepi ACTA2+ | 1 |
| 4 | AAACAAGCAACTAAAC-1 | Myoepi ACTA2+ | 4 |
# first we ensure that there are no missing values and combine annotations with the edges dataframe
edges_enc, annotations_enc = dataset.preprocess_data(edges, annotations,"sc2vis","vis2grid")
edges_enc.head()
| node1 | node2 | weight | type | clone | cell_type | |
|---|---|---|---|---|---|---|
| 0 | TGAGCGATCACTAATC-1 | AACACCTACTATCGAA-1 | 0.909754 | sc2vis | 1 | Stromal |
| 1 | GATCGATAGGAAGGTA-1 | AACACCTACTATCGAA-1 | 0.909715 | sc2vis | 1 | Stromal |
| 2 | CAGTATTTCGGCTAGA-1 | AACACCTACTATCGAA-1 | 0.887354 | sc2vis | diploid | Stromal |
| 3 | AAGGCTTAGTGCCCTG-1 | AACACCTACTATCGAA-1 | 0.860617 | sc2vis | 1 | T Cell & Tumor Hybrid |
| 4 | CCCTTCGGTGACACAA-1 | AACACCTACTATCGAA-1 | 0.857889 | sc2vis | 1 | Stromal |
# specify paths to the embeddings that we will use as features for the nodes. Please don't modify unless you previously saved the embeddings in a different location
embedding_paths = {"spatial":f"../data/tmp/embedding_spatial_.csv",
"rna":f"../data/tmp/embedding_rna_.csv"}
#next we encode all strings as ingeres and ensure consistancy between the edges and the annotations
emb_vis_nodes, emb_rna_nodes, edges_enc, node_encoder = dataset.read_and_merge_embeddings(embedding_paths, edges_enc)
Excluding 0 clones with less than 10 cells
Excluding 0 cell types with less than 10 cells
edges_enc.head()
| node1 | node2 | weight | type | clone | cell_type | |
|---|---|---|---|---|---|---|
| 0 | 21197 | 28356 | 0.909754 | sc2vis | 1 | Stromal |
| 1 | 6820 | 28356 | 0.909715 | sc2vis | 1 | Stromal |
| 2 | 32167 | 28356 | 0.887354 | sc2vis | diploid | Stromal |
| 3 | 11731 | 28356 | 0.860617 | sc2vis | 1 | T Cell & Tumor Hybrid |
| 4 | 1325 | 28356 | 0.857889 | sc2vis | 1 | Stromal |
#make sure that weight is a float
edges_enc.weight = edges_enc.weight.astype(float)
#Finally creating a pytorch dataset object and a dictionaru that will be used for decoding the data
data, encoding_dict = dataset.create_data_object(edges_enc, emb_vis_nodes, emb_rna_nodes, node_encoder)
torch.save(data, "../data/tmp/data_visium.pt")
with open('../data/tmp/full_encoding_visium.pkl', 'wb') as fp:
pickle.dump(encoding_dict, fp)
2: Running spaceTree
2.1: Load the data and ID encoder/decoder dictionaries
data = torch.load("../data/tmp/data_visium.pt")
with open('../data/tmp/full_encoding_visium.pkl', 'rb') as handle:
encoder_dict = pickle.load(handle)
node_encoder_rev = {val:key for key,val in encoder_dict["nodes"].items()}
node_encoder_clone = {val:key for key,val in encoder_dict["clones"].items()}
node_encoder_ct = {val:key for key,val in encoder_dict["types"].items()}
data.edge_attr = data.edge_attr.reshape((-1,1))
2.2: Separate spatial nodes from reference nodes
hold_out_indices = np.where(data.y_clone == -1)[0]
hold_out = torch.tensor(hold_out_indices, dtype=torch.long)
total_size = data.x.shape[0] - len(hold_out)
train_size = int(0.8 * total_size)
# Get indices that are not in hold_out
hold_in_indices = np.arange(data.x.shape[0])
hold_in = [index for index in hold_in_indices if index not in hold_out]
2.3: Create test set from reference nodes
# Split the data into train and test sets
train_indices, test_indices = utils.balanced_split(data,hold_in, size = 0.3)
# Assign the indices to data masks
data.train_mask = torch.tensor(train_indices, dtype=torch.long)
data.test_mask = torch.tensor(test_indices, dtype=torch.long)
# Set the hold_out data
data.hold_out = hold_out
2.3: Create weights for the NLL loss to ensure that the model learns the correct distribution of cell types and clones
y_train_type = data.y_type[data.train_mask]
weight_type_values = utils.compute_class_weights(y_train_type)
weight_type = torch.tensor(weight_type_values, dtype=torch.float)
y_train_clone = data.y_clone[data.train_mask]
weight_clone_values = utils.compute_class_weights(y_train_clone)
weight_clone = torch.tensor(weight_clone_values, dtype=torch.float)
data.num_classes_clone = len(data.y_clone.unique())
data.num_classes_type = len(data.y_type.unique())
2.4: Create Neigborhor Loader for efficient training
del data.edge_type
train_loader = NeighborLoader(
data,
num_neighbors=[10] * 3,
batch_size=128,input_nodes = data.train_mask
)
valid_loader = NeighborLoader(
data,
num_neighbors=[10] * 3,
batch_size=128,input_nodes = data.test_mask
)
2.5: Specifying the device and sending the data to the device
device = torch.device('cuda:0')
data = data.to(device)
weight_clone = weight_clone.to(device)
weight_type = weight_type.to(device)
data.num_classes_clone = len(data.y_clone.unique())
data.num_classes_type = len(data.y_type.unique())
2.6: Model specification and training
lr = 0.01
hid_dim = 50
head = 2
wd = 0.001
model = GATLightningModule_sampler(data,
weight_clone, weight_type, learning_rate=lr,
heads = head, dim_h = hid_dim, weight_decay= wd)
model = model.to(device)
early_stop_callback = pl.callbacks.EarlyStopping(monitor="validation_combined_loss", min_delta=1e-4, patience=10, verbose=True, mode="min")
trainer1 = pl.Trainer(max_epochs=1000, accelerator = "gpu", devices = [0],
callbacks = [early_stop_callback],
log_every_n_steps=10)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
trainer1.fit(model, train_loader, valid_loader)
You are using a CUDA device ('NVIDIA GeForce RTX 4090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: /data2/olga/clonal_GNN/notebooks/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
| Name | Type | Params
-------------------------------
0 | model | GAT2 | 15.5 K
-------------------------------
15.5 K Trainable params
0 Non-trainable params
15.5 K Total params
0.062 Total estimated model params size (MB)
Epoch 0: 100%|██████████| 151/151 [00:01<00:00, 90.32it/s, v_num=0, validation_acc_clone=0.713, validation_acc_ct=0.682, validation_combined_loss=0.000742, train_combined_loss=1.400]
Metric validation_combined_loss improved. New best score: 0.001
Epoch 2: 100%|██████████| 151/151 [00:01<00:00, 99.34it/s, v_num=0, validation_acc_clone=0.727, validation_acc_ct=0.716, validation_combined_loss=0.000614, train_combined_loss=0.931]
Metric validation_combined_loss improved by 0.000 >= min_delta = 0.0001. New best score: 0.001
Epoch 8: 100%|██████████| 151/151 [00:01<00:00, 99.72it/s, v_num=0, validation_acc_clone=0.731, validation_acc_ct=0.754, validation_combined_loss=0.000508, train_combined_loss=0.801]
Metric validation_combined_loss improved by 0.000 >= min_delta = 0.0001. New best score: 0.001
Epoch 18: 100%|██████████| 151/151 [00:01<00:00, 99.70it/s, v_num=0, validation_acc_clone=0.744, validation_acc_ct=0.782, validation_combined_loss=0.000461, train_combined_loss=0.752]
Monitored metric validation_combined_loss did not improve in the last 10 records. Best score: 0.001. Signaling Trainer to stop.
Epoch 18: 100%|██████████| 151/151 [00:01<00:00, 99.34it/s, v_num=0, validation_acc_clone=0.744, validation_acc_ct=0.782, validation_combined_loss=0.000461, train_combined_loss=0.752]
# Predction on spatial data
model.eval()
model = model.to(device)
with torch.no_grad():
out, w, _ = model(data)
# Decoding the results back to the original format
clone_res,ct_res= utils.get_calibrated_results(out, data, node_encoder_rev, node_encoder_ct,node_encoder_clone, 4)
clone_res.head()
| 0 | 1 | 2 | 3 | 4 | diploid | |
|---|---|---|---|---|---|---|
| ATGGAGCGCACTCGGT-1 | 0.164629 | 0.201548 | 0.087236 | 0.361839 | 0.127989 | 0.056760 |
| TATTCGTGCGTTCTGG-1 | 0.139463 | 0.233542 | 0.141513 | 0.144796 | 0.131624 | 0.209062 |
| GATAAGTTGGCGATTA-1 | 0.119130 | 0.245921 | 0.155518 | 0.118340 | 0.041221 | 0.319870 |
| TAAGTGCTTGACGATT-1 | 0.228791 | 0.295177 | 0.122400 | 0.147830 | 0.109177 | 0.096625 |
| AGCTATAGAATAGTCT-1 | 0.136758 | 0.239236 | 0.146668 | 0.137973 | 0.070588 | 0.268777 |
ct_res.head()
| Invasive Tumor | Stromal | Endothelial | CD8+ T Cells | CD4+ T Cells | DCIS 2 | B Cells | Macrophages 1 | Prolif Invasive Tumor | DCIS 1 | Perivascular-Like | Myoepi KRT15+ | Myoepi ACTA2+ | T Cell & Tumor Hybrid | Macrophages 2 | LAMP3+ DCs | IRF7+ DCs | Stromal & T Cell Hybrid | Mast Cells | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ATGGAGCGCACTCGGT-1 | 0.113601 | 0.074405 | 0.045121 | 0.031819 | 0.012398 | 0.170356 | 0.039903 | 0.057007 | 0.071912 | 0.045266 | 0.036586 | 0.044900 | 0.121862 | 0.063887 | 0.011587 | 0.012855 | 0.016948 | 0.014756 | 0.014829 |
| TATTCGTGCGTTCTGG-1 | 0.055364 | 0.114338 | 0.067072 | 0.033947 | 0.037124 | 0.044074 | 0.088799 | 0.081469 | 0.019588 | 0.043440 | 0.074773 | 0.040905 | 0.055184 | 0.040249 | 0.039944 | 0.029687 | 0.031319 | 0.076761 | 0.025964 |
| GATAAGTTGGCGATTA-1 | 0.031130 | 0.253855 | 0.139259 | 0.005972 | 0.026194 | 0.028109 | 0.042881 | 0.097040 | 0.002196 | 0.051367 | 0.121213 | 0.038432 | 0.038635 | 0.019400 | 0.021456 | 0.009946 | 0.017761 | 0.049659 | 0.005495 |
| TAAGTGCTTGACGATT-1 | 0.173712 | 0.072336 | 0.062718 | 0.040325 | 0.076782 | 0.050060 | 0.061539 | 0.041365 | 0.076631 | 0.058009 | 0.031356 | 0.042110 | 0.038241 | 0.103945 | 0.007016 | 0.014150 | 0.017885 | 0.016237 | 0.015583 |
| AGCTATAGAATAGTCT-1 | 0.039850 | 0.176047 | 0.108191 | 0.011887 | 0.026710 | 0.036671 | 0.055716 | 0.110701 | 0.006598 | 0.043542 | 0.112135 | 0.037759 | 0.045568 | 0.026184 | 0.038007 | 0.018513 | 0.025663 | 0.067560 | 0.012696 |
3: Results and visualization
visium.obs = visium.obs.join(clone_res).join(ct_res)
3.1: Clon mapping
First we will visualize the clone mapping results and compare them to the histological annotation provided by the authors:
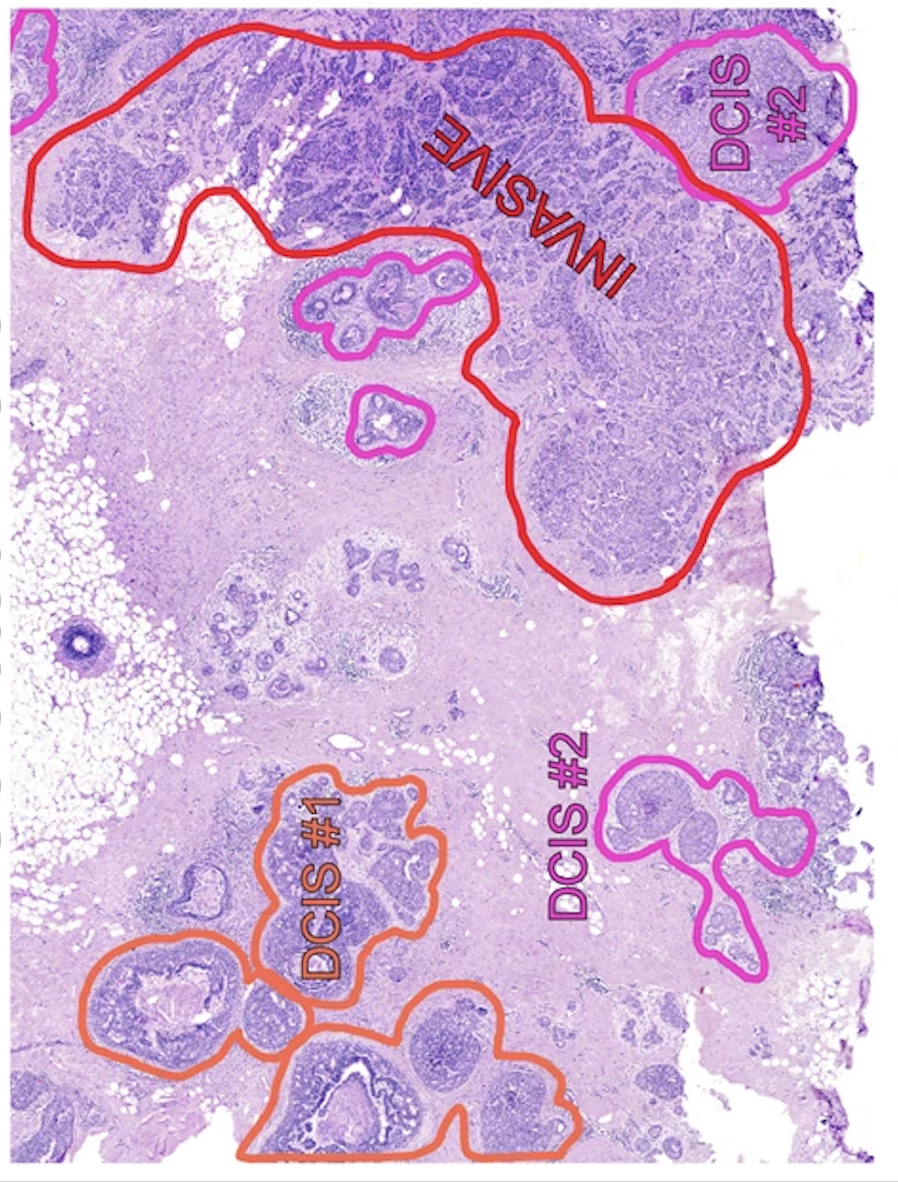
(note that the images are not fully overlapping)
sc.pl.spatial(visium, color = clone_res.columns, ncols=2)
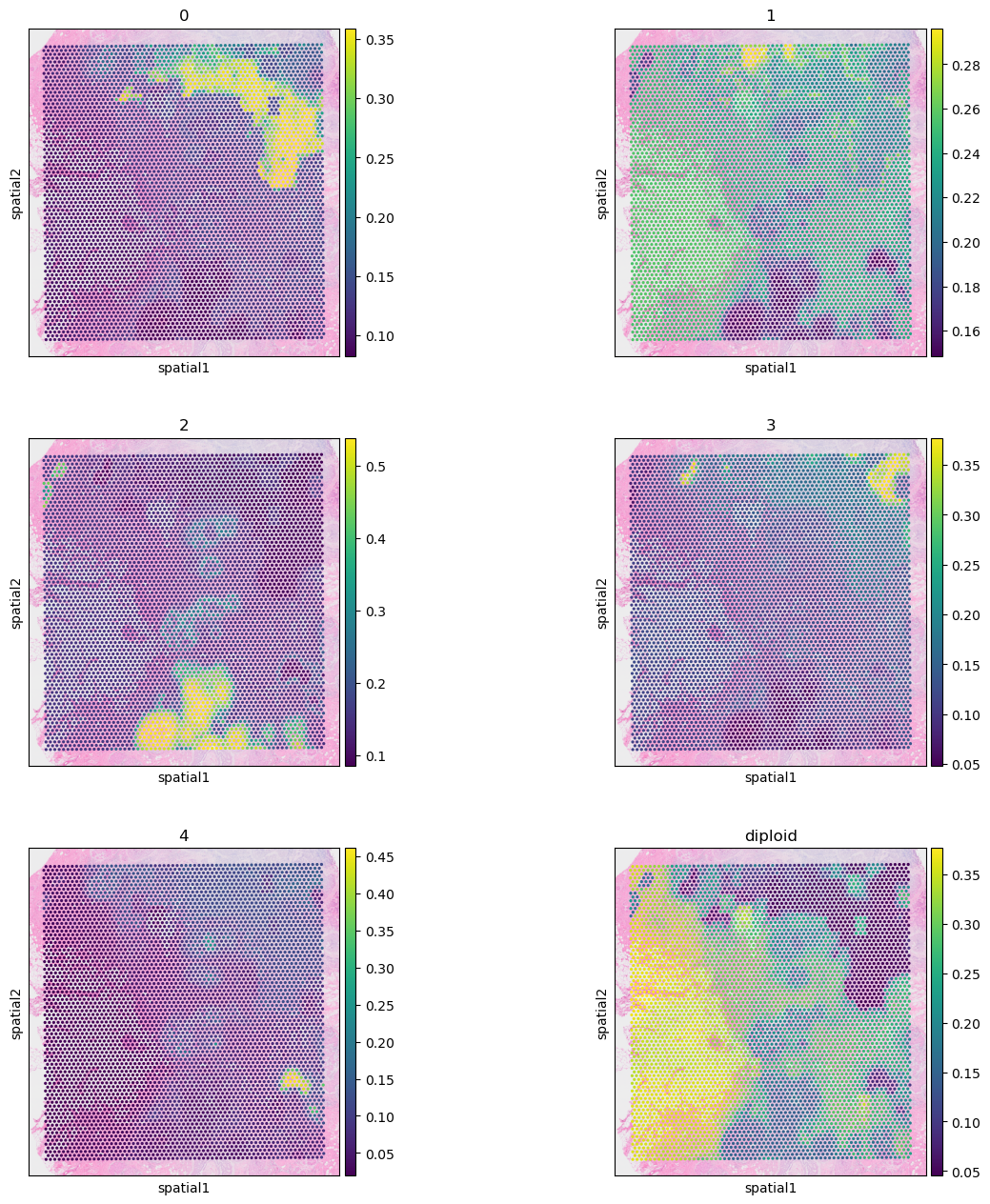
We can see that invasive tumor alligns with clone 0, DCIS 1 with clone 2, DCIS 2 with clone 3 (top part) and 4 (right part). Interestingly, that DCIS 2 was separated into two clones with distinct spatial locations. Indeed, despite being classified as a single DCIS, those clones have distinct CNV patterns (e.g. chr3 and chr19):
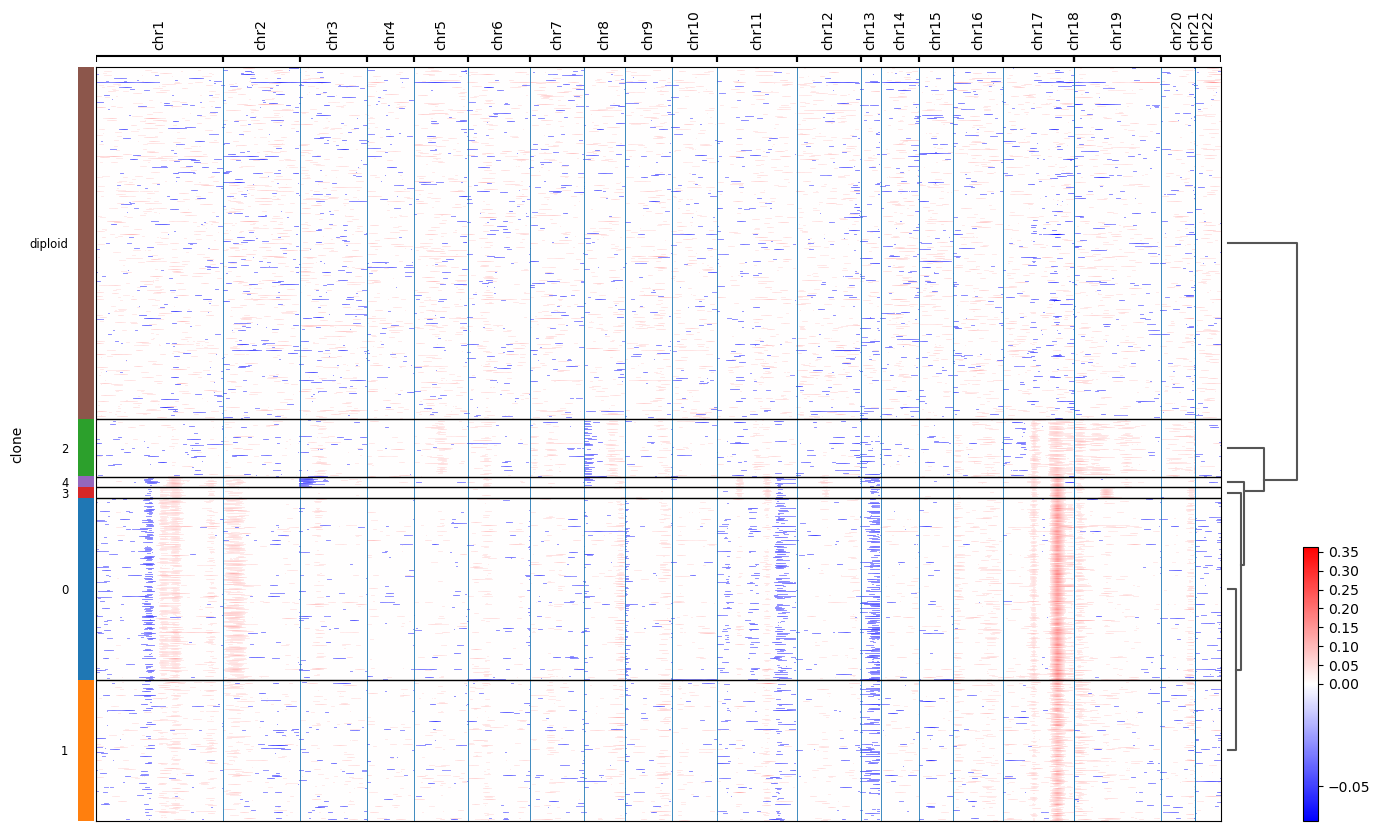
(the image is taken from ../docs//infercnv_run.ipynb)
3.2: Cell type mapping
We can also visualise the cell type mapping to confirm that the results allign with the original publication:
sc.pl.spatial(visium, color = ct_res.columns, ncols=3)